Leveraging cloud technology for GIS analysis with OpenStreetMap
To increase accessibility, ease of maintenance and enable efficient analysis of OpenStreetMap data, we look at leveraging cloud technology
With OpenStreetMap being one of the most widespread and most frequently updated open geospatial datasets, it is has become popular among map enthusiasts and GIS professionals. Due to its high volume and frequent updates, cloud technology could be leveraged to provide an efficient environment that is easily accessible and maintained.
Being a major player in cloud platform, Amazon Web Services (AWS) hosts a registry of publicly available datasets 1 accessible via its resources. Among the datasets relevant to GIS analysis, OpenStreetMap planet data was one of them. Amazon Athena 2 service makes the OpenStreetMap planet data easily accessible for query, analysis and export.
This post will detail the steps to set up the OpenStreetMap planet table on Athena, mention a couple of useful features of Athena and demonstrate the automation of the weekly refresh of the latest OpenStreetMap planet data made available on AWS.
Pre-requisites
- Have an AWS account, with necessary permissions to AWS S3 and Athena
Setting up planet table on Athena
When using Athena for the first time, there will be a warning that requires an AWS S3 location for storing query results. If there isn’t a designated bucket created already, do so; else we just click on the warning for a form to specify the bucket location.
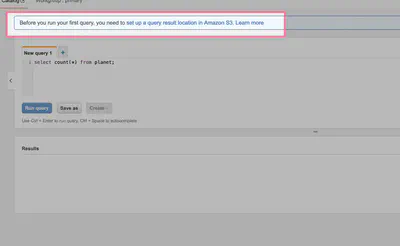
Using the query editor, we create the default database using the SQL query below.
CREATE DATABASE IF NOT EXISTS `default`;
Then we will create the planet table with the following query:
CREATE EXTERNAL TABLE planet (
id BIGINT,
type STRING,
tags MAP<STRING,STRING>,
lat DECIMAL(9,7), -- for nodes
lon DECIMAL(10,7), -- for nodes
nds ARRAY<STRUCT<ref: BIGINT>>, -- for ways
members ARRAY<STRUCT<type: STRING, ref: BIGINT, role: STRING>>, -- for relations
changeset BIGINT,
timestamp TIMESTAMP,
uid BIGINT,
user STRING,
version BIGINT
)
STORED AS ORCFILE
LOCATION 's3://osm-pds/planet/';
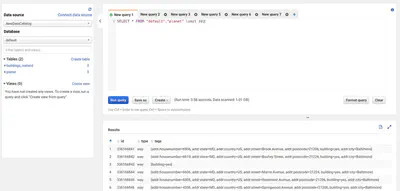
After this, we can do a quick preview of the table to check on the imported data.
SELECT * FROM planet LIMIT 10;
Useful Features of Athena
Athena offers some useful features such as Saved Queries, where we could save queries we often use.
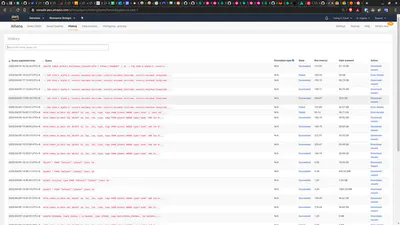
Also, the Query History shows all prior query attempts and their outcome. This is particularly useful to get an idea of the volume of data we have queried.
Very often, it is useful saved the query output as a table or view, or export to be downloaded. The supported export formats are as shown below:
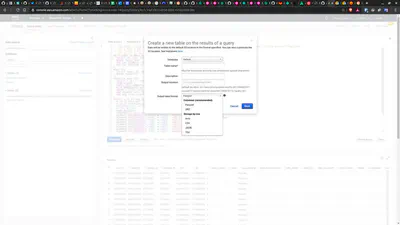
The output files are available in the S3 bucket configured earlier.
As this post is being written, AWS Athena export supports export format in Parquet, ORC, AVRO, CSV, JSON and TSV.
When deciding the output format, it is useful to keep in mind these considerations3:
- Read/Write Intensive & Query Pattern
- Compression
- Schema Evaluation
- Nested Column
- Platform
Automate refresh of planet data
Not only the set up of OpenStreetMap planet on Athena is easy, its maintenance and periodic refresh of the latest data can also be automated with a simple script.
Although some OpenStreetMap sources on some websites are updated daily, the OpenStreetMap dataset on AWS is only updated once a week. When that happens, we want to update the planet table for the latest version. Instead of performing the update manually, we can automate the boring stuff, set up crontab to run the following script to perform the update.
The script requires AWS SDK for Python (Boto3), AWS Boto3 and PyAthena.
from pyathena import connect
cursor = connect(aws_access_key_id='XXXXX',
aws_secret_access_key='XXXXX',
s3_staging_dir='s3://bucket-for-staging/',
region_name='ap-southeast-1').cursor()
create_db_sql = """
CREATE DATABASE IF NOT EXISTS default;
"""
drop_table_sql = """
DROP TABLE IF EXISTS planet;
"""
refresh_planet_sql = """
CREATE EXTERNAL TABLE planet (
id BIGINT,
type STRING,
tags MAP<STRING,STRING>,
lat DECIMAL(9,7),
lon DECIMAL(10,7),
nds ARRAY<STRUCT<ref: BIGINT>>,
members ARRAY<STRUCT<type: STRING, ref: BIGINT, role: STRING>>,
changeset BIGINT,
timestamp TIMESTAMP,
uid BIGINT,
user STRING,
version BIGINT
)
STORED AS ORCFILE
LOCATION 's3://osm-pds/planet/';
"""
cursor.execute(create_db_sql)
cursor.execute(drop_table_sql)
try:
cursor.execute(refresh_planet_sql)
print("Table `planet` is updated.")
except Exception as e:
print(e)
print(cursor.description)
Other Considerations
Working with cloud technology often means having a 3rd party hosting our private data and/or intellectual properties. We should be mindful to choose the region/country where these properties are judicially bound.
Last but not least, it is also important to follow security best practices, such as enforcing secure and complex passwords, assigning only the minimum permissions required, enabling multi-factor authentication, to ensure our private data and intellectual properties are protected.