Abstract
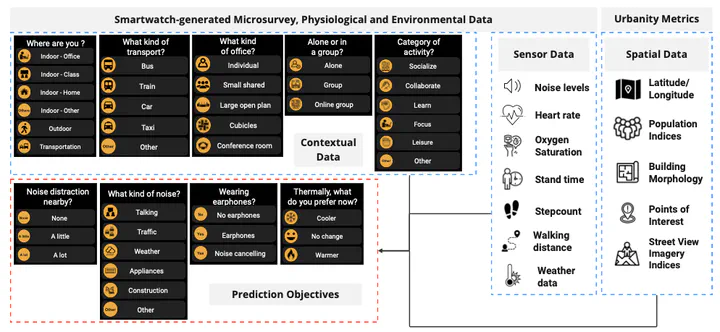
The prediction of thermal and noise-based preferences in the urban context is valuable in characterizing interventions to mitigate the challenges of health, productivity, and satisfaction of urban dwellers. The growth of crowd-sourced data and data-driven techniques provides an opportunity to increase the understanding of which machine learning models are most accurate and applicable for this context. This paper outlines the results of a machine learning competition aiming to enhance the accuracy of predicting human comfort in the city context. The competition asks contestants to use contextual data to predict noise distraction and thermal preference in various indoor and outdoor spaces. This competition included the city-scale collection of 9,808 smartwatch-driven micro-survey responses that were collected alongside 2,659,764 physiological and environmental measurements from 98 people using an open-source watch-based platform combined with geolocation-driven urban digital twin metrics. This paper explains the two best solutions to this competition and provides a discussion of the factors that may have contributed to their accuracy of more than 0.7 in multiclass tasks. These solutions notably included the use of LightGBM, XGBoost, CatBoost, and simple Neural Networks while avoiding overly complex solutions such as deep learning or recurrent architectures, which offer limited advantages for structured data classifications.