Learning Fine-Grained Urban Mobility Dynamics Through Large Model-Enhanced Multimodal Representations
Abstract
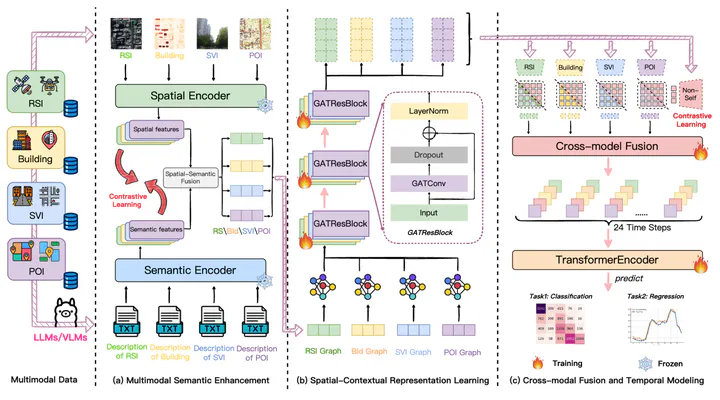
Accurately predicting fine-grained urban mobility is essential for optimizing transportation, accessibility, and urban management. However, existing approaches often depend on dynamic data such as trajectories or signaling records, which are sparsely available across cities, thereby limiting their applicability and generalizability to new urban contexts. To address these limitations, this study proposes a Large Model Enhanced Multimodal Representations (LMEMR) framework to learn hourly grid-level mobility dynamics solely from static geospatial data—including remote sensing imagery, building data, street view imagery, and points of interest—which are widely accessible. Large vision–language models are employed to generate natural-language descriptions of each modality, enriching the data with human-understandable semantics. A dual-level contrastive learning strategy aligns raw and textual features both within and across modalities, mitigating semantic gaps and enhancing multimodal consistency. Spatial dependencies are modeled through a graph attention network, and temporal dynamics are captured via a transformer encoder to produce 24-hour mobility sequences. Results from Shenzhen demonstrate that LMEMR outperforms the baseline CLIP model, achieving an $R^{2}$ of 0.856and an 18.07% reduction in MAE. Ablation experiments confirm the effectiveness of semantic enhancement, spatial graph reasoning, and cross-modal fusion. Overall, this research reveals the potential of static multimodal data for dynamic mobility inference, offering a scalable, interpretable, and privacy-friendly solution for smart city planning and management.